 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiCaps: Iterative Category-level Object Pose and Shape Estimation
Dec 31, 2021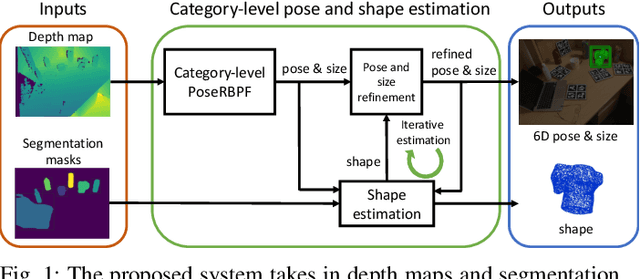
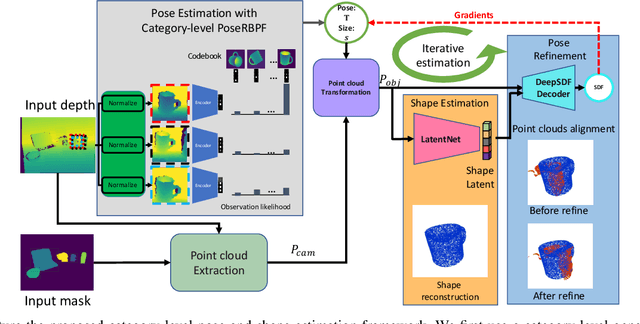
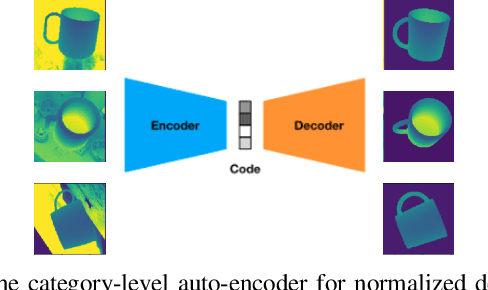
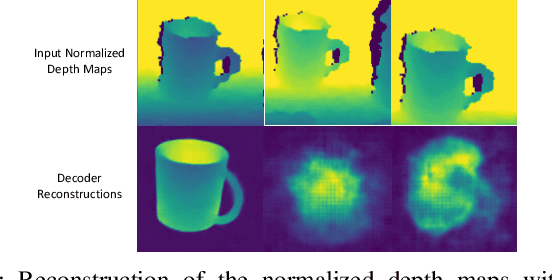
This paper proposes a category-level 6D object pose and shape estimation approach iCaps, which allows tracking 6D poses of unseen objects in a category and estimating their 3D shapes. We develop a category-level auto-encoder network using depth images as input, where feature embeddings from the auto-encoder encode poses of objects in a category. The auto-encoder can be used in a particle filter framework to estimate and track 6D poses of objects in a category. By exploiting an implicit shape representation based on signed distance functions, we build a LatentNet to estimate a latent representation of the 3D shape given the estimated pose of an object. Then the estimated pose and shape can be used to update each other in an iterative way. Our category-level 6D object pose and shape estimation pipeline only requires 2D detection and segmentation for initialization. We evaluate our approach on a publicly available dataset and demonstrate its effectiveness. In particular, our method achieves comparably high accuracy on shape estimation.
Motion Reasoning for Goal-Based Imitation Learning
Nov 13, 2019
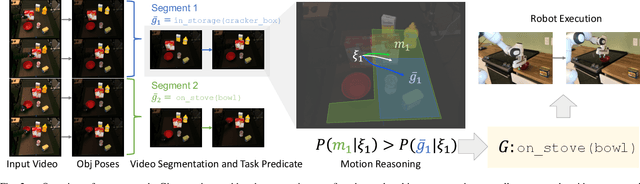
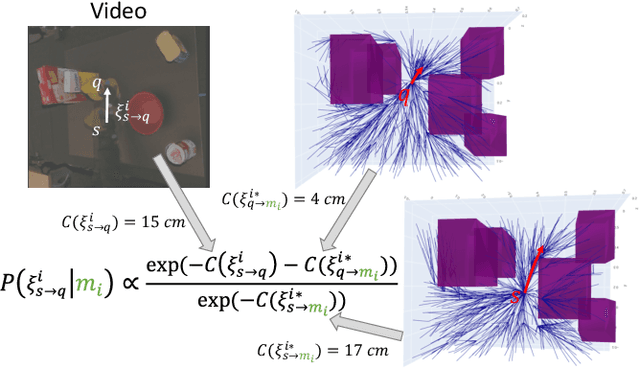

We address goal-based imitation learning, where the aim is to output the symbolic goal from a third-person video demonstration. This enables the robot to plan for execution and reproduce the same goal in a completely different environment. The key challenge is that the goal of a video demonstration is often ambiguous at the level of semantic actions. The human demonstrators might unintentionally achieve certain subgoals in the demonstrations with their actions. Our main contribution is to propose a motion reasoning framework that combines task and motion planning to disambiguate the true intention of the demonstrator in the video demonstration. This allows us to robustly recognize the goals that cannot be disambiguated by previous action-based approaches. We evaluate our approach by collecting a dataset of 96 video demonstrations in a mockup kitchen environment. We show that our motion reasoning plays an important role in recognizing the actual goal of the demonstrator and improves the success rate by over 20%. We further show that by using the automatically inferred goal from the video demonstration, our robot is able to reproduce the same task in a real kitchen environment.
Self-supervised 6D Object Pose Estimation for Robot Manipulation
Sep 23, 2019
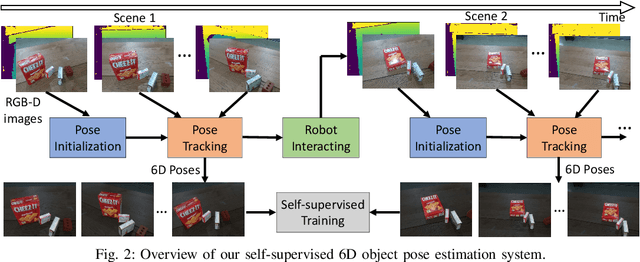
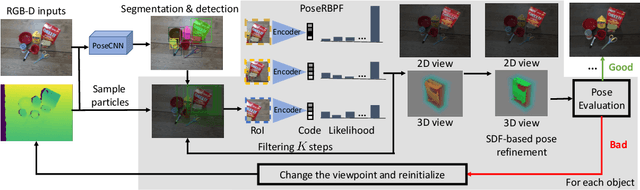
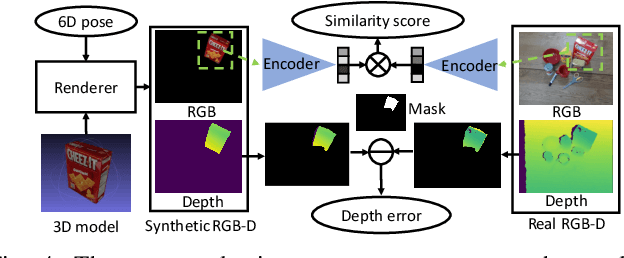
To teach robots skills, it is crucial to obtain data with supervision. Since annotating real world data is time-consuming and expensive, enabling robots to learn in a self-supervised way is important. In this work, we introduce a robot system for self-supervised 6D object pose estimation. Starting from modules trained in simulation, our system is able to label real world images with accurate 6D object poses for self-supervised learning. In addition, the robot interacts with objects in the environment to change the object configuration by grasping or pushing objects. In this way, our system is able to continuously collect data and improve its pose estimation modules. We show that the self-supervised learning improves object segmentation and 6D pose estimation performance, and consequently enables the system to grasp objects more reliably. A video showing the experiments can be found at https://youtu.be/W1Y0Mmh1Gd8.
PoseRBPF: A Rao-Blackwellized Particle Filter for 6D Object Pose Tracking
May 22, 2019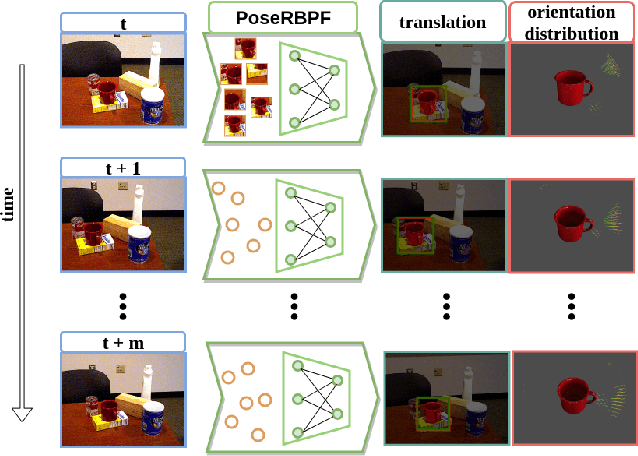
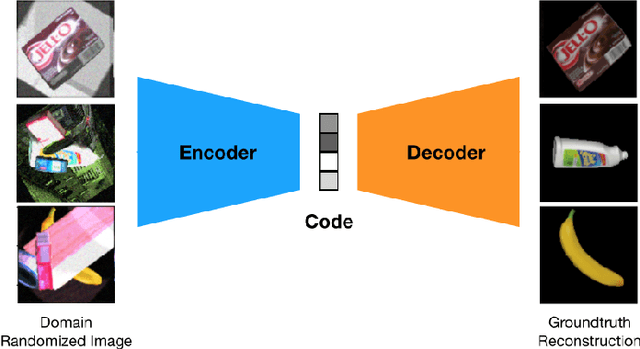
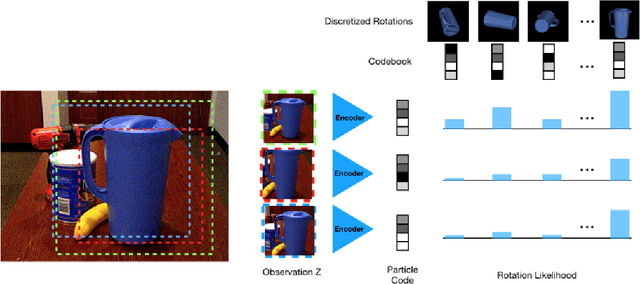
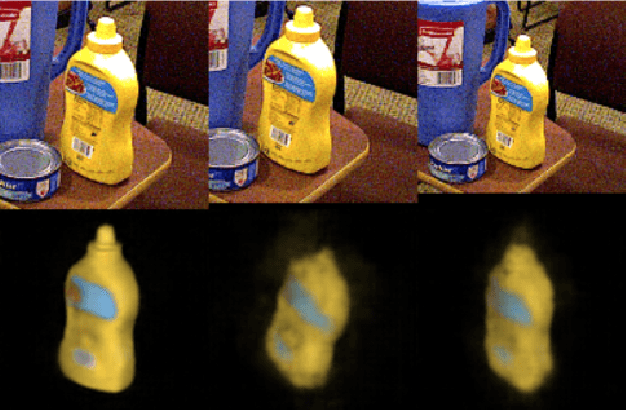
Tracking 6D poses of objects from videos provides rich information to a robot in performing different tasks such as manipulation and navigation. In this work, we formulate the 6D object pose tracking problem in the Rao-Blackwellized particle filtering framework, where the 3D rotation and the 3D translation of an object are decoupled. This factorization allows our approach, called PoseRBPF, to efficiently estimate the 3D translation of an object along with the full distribution over the 3D rotation. This is achieved by discretizing the rotation space in a fine-grained manner, and training an auto-encoder network to construct a codebook of feature embeddings for the discretized rotations. As a result, PoseRBPF can track objects with arbitrary symmetries while still maintaining adequate posterior distributions. Our approach achieves state-of-the-art results on two 6D pose estimation benchmarks. A video showing the experiments can be found at https://youtu.be/lE5gjzRKWuA